
Hasura vs Prisma
Over the last few weeks, many people have asked me what the difference between Hasura & Prisma is.
I’ve put together a few points below with help from how our users are using Hasura, to list out a few differences. These are qualitative points and in the interest of time I’ve not been very exhaustive and I will gradually do so. Please feel free to reach out to me on twitter or on discord(@tanmaig) if you have any questions in the meantime.
On the surface, Hasura and Prisma provide a GraphQL API over Postgres. However, there is a significant difference in terms of where Hasura ideally fits in your stack and how they add value to your project.
Hasura is GraphQL for your frontend apps.
Prisma is a GraphQL ORM for your GraphQL (or REST) servers and not your frontend apps, kind of like a replacement for JDBC, SQL Alchemy, ActiveRecord and so on.
Prisma as a GraphQL API over your database cannot be used directly by your frontend apps.
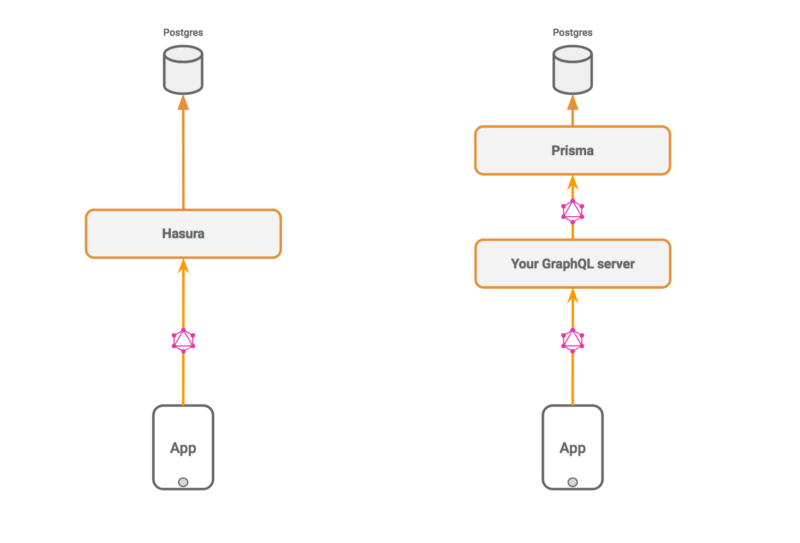
That said, you can use Hasura as a GraphQL API for your microservices if you need to. Especially if you’re looking for scalable and robust subscriptions.
Adding business logic
Prisma has clients & bindings for a nodejs/typescript/go for you to build your own business logic that would talk to a database. Because Prisma is an ORM, instead of using, say, nodejs and knex/sequelize to build a GraphQL server, you can use nodejs and Prisma client to speak to the Prisma server to speak to the database. Your code can perform business logic as usual, exactly like you would when building a GraphQL server from scratch.
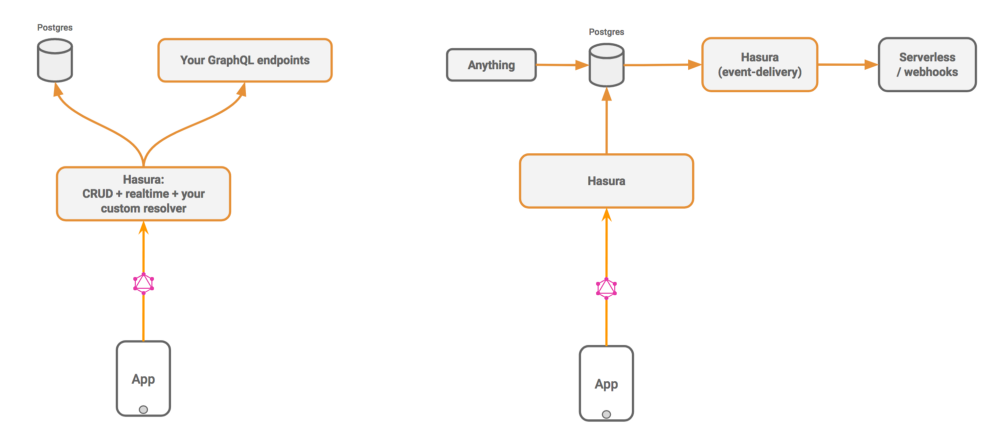
With Hasura, there are 2 ways to write business logic:
- You write your own GraphQL service however you’d like, in any language/framework, using your favourite ORM (if you need to speak to the database) and merge that GraphQL service with Hasura’s GraphQL to create a unified GraphQL endpoint.
- You write a webhook, ideally as a serverless function, that gets triggered whenever any changes happen in the database. Note that you can setup change capture for any change in the database, not just when there are GraphQL mutations.
Hasura aims to save you the grunt effort of writing a CRUD and scalable realtime backend without interfering with how you’d write your business logic.
Auth/access control and GraphQL security
Because Hasura is a GraphQL API for your apps, Hasura has access control and authorization features for you to be able to secure access to your database. We’ve carefully designed the access-control system to be able to handle simple to complex use-cases. From users being able to CRUD their own data to enterprise-grade multi-tenant, multi-role applications.
Hasura integrates with any auth system, including JWT systems like Auth0, firebase, forgerock.
GraphQL security: We already support limiting response sizes to prevent scraping/denial-of-service and we’re adding more security features prioritized by what our users want. There are lots of other features we have on our roadmap for our users to help them use GraphQL securely.
Performance & cost
Hasura does not use resolvers or a data-loader in its architecture. Instead, Hasura compiles a GraphQL query to a single, very readable, SQL query that include access-control clauses (where user_id = <session-user-id>). This makes Hasura extremely fast, especially for complex queries. Read more about our high performance architecture here: https://hasura.io/blog/architecture-of-a-high-performance-graphql-to-sql-server-58d9944b8a87
Because Hasura is actually a compiler fronted by a webserver, Hasura’s resource footprint is insanely low, especially compared to the JVM that Prisma needs to run.
Hasura can service a few thousand complex GraphQL queries per second well within a 100MB of RAM → Build a side-project that scales to a thousand concurrent users at 5$ a month running both Postgres and Hasura. Prisma cannot run on the Heroku free tier or on Zeit because of its image size and resource consumption.
In comparison, Prisma uses the dataloader approach and is optimized for small queries only and can’t handle complex queries efficiently.
Simple scaling & auto-scaling
Hasura is designed to be completely stateless and does not have a master-slave architecture. This makes it painless to scale Hasura:
- Vertical scaling: Increase CPU/RAM
- Horizontal scaling: Increase the number of replicas
- Auto-scaling: Setup up auto-scaling on your favourite container provider for automatic 1 to n scaling depending on traffic
Because of this, setting up production architectures for Hasura that involve auto-scaling, multi-AZ deployments, HA configurations is a straightforward process.
Horizontally scaling Prisma is more tedious and not as straightforward as changing a config variable to increase replicas or enabling auto-scaling on your cloud vendor dashboard (or declarative config file).
Seamless support for Postgres
Hasura is designed to be Postgres first. Postgres is a very mature database and Hasura ensures that you can keep using an existing Postgres instance the way you want without any changes to your team’s workflow. Hasura supports Postgres rich type system and operators, the ability to create views, using custom SQL functions and very soon even materialized views!
Automatic management of your GraphQL schema
Prisma makes you manage a database exclusively via the GraphQL SDL which cannot support the kinds of up/down/customisable database migrations that most applications eventually need. Eg, in a GraphQL SDL driven database system: Creating a User GraphQL type is equivalent to creating a user table.
Hasura does not drive your data model through the GraphQL schema definition language. Instead Hasura helps you use your database as you would and offers a simple UI to manage your database modelling, and then generates a GraphQL schema on top of that based on extra metadata you give it. You can use your own database migration system or Hasura’s migration system (inspired by ActiveRecord ala Rails) to model your database.



