
Tweaking GraphQL performance using Postgres’ Explain command

Leveraging Postgres’ execution plan information to find performance bottlenecks
As the Hasura GraphQL Engine’s API is meant to be consumed concurrently by many frontend client apps, we’ve invested a significant amount of effort into ensuring that Hasura is super performant (in terms of latency and resource consumption) and inherently scalable. In this post, let’s see how we introduced a performance analysis feature for users by leveraging Postgres’ popular execution plan analysis tool, Explain.
Performance in Hasura GraphQL Engine
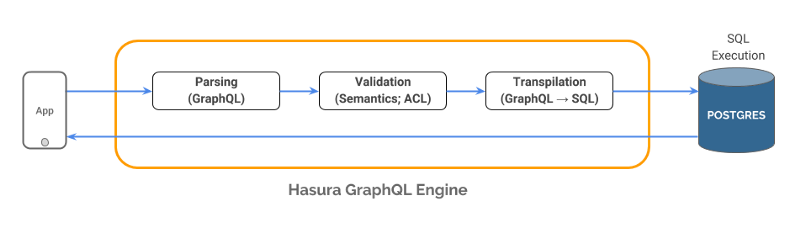
An incoming request to Hasura goes through the following stages:
- The request body is parsed into a GraphQL AST
- The GraphQL query is validated (checks for semantic correctness and ACL/authorization), and, if it passes all checks,
- The validated query is converted to an SQL statement and is executed by Postgres (which also converts the resultset into JSON)
- The JSON response is returned to the client.
We have previously blogged about the architectural decisions made for optimizing the performance of the Hasura GraphQL Engine. Network latencies are also negligible as Hasura and the configured Postgres instance are meant to be collocated in the same datacenter/network. So, that leaves database optimizations, like indexes, etc. as options critical to improving the performance of the GraphQL API. These optimizations are largely dependent on the database schema and the quantum of data being handled.
Postgres’ Explain command displays the execution plan generated for the supplied SQL statement. The execution plan shows how the table(s) referenced by the statement will be scanned, and if multiple tables are referenced, what join algorithms will be used to bring together the required rows from each input table, along with estimated statement execution cost (Postgres docs; check out this post on how to interpret a Postgres execution plan).
In a recent version of Hasura GraphQL Engine, we introduced an API that takes a GraphQL query as input and outputs the generated SQL along with the execution plan prepared by the Explain command.
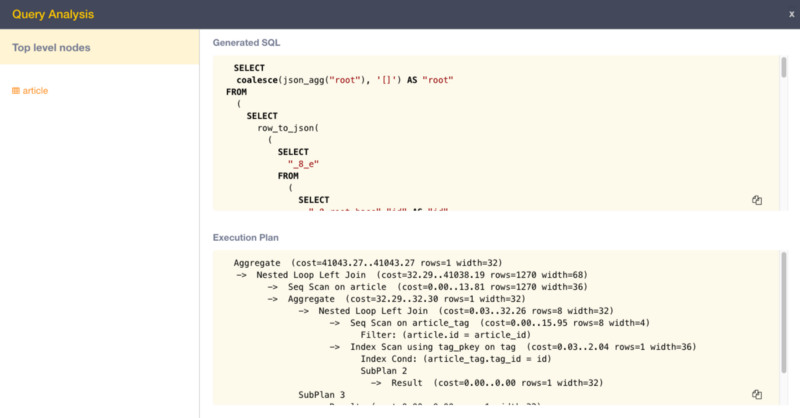
Let’s see how this feature helps tweak the performance of GraphQL queries through an anecdote.
From 30s → less than 1s
A user from the community reported alarmingly high latency numbers for one of their queries — 30 seconds! The query fetches data from two tables, MrSeries and MrVolume, each with a few million rows in it. Here’s a modified version of that query:
And, here’s the corresponding execution plan for it from the Explain command:
Performance bottlenecks are the steps with high associated costs (cost is an arbitrary unit of computation). In the above execution plan, it’s easy to see that the bottlenecks are lines 11 and 14 — Postgres running sequential scans on the tables MrSeries and MrVolume, which is bad as there are millions of rows in them! To rectify this, we added a couple of indexes on these tables:
Then, we ran the following SQL commands to update Postgres’ stats about these tables:
When we ran and analyzed the query again, here’s what we saw:
Notice how the aggregate cost came down from 2439653.09 to 174088.71 (a ~14x drop!). The latency also went down from ~30 seconds to less than 1 second! All this from just adding a couple of indexes. How awesome is that?! ???
We are iterating on this feature to make the insights from Explain readily actionable, automatically highlight performance bottlenecks, and perhaps even automate the database admin tasks for developers! ?
How to check out this feature
Deploy the Hasura GraphQL Engine (Heroku is the fastest way to try it out) and create a table or two using the admin console (also seed it with some test data). Head to the GraphiQL tab of the console and run any valid GraphQL query based on your tables. Click on the Analyze button to see the execution plan and the generated SQL for your GraphQL query!
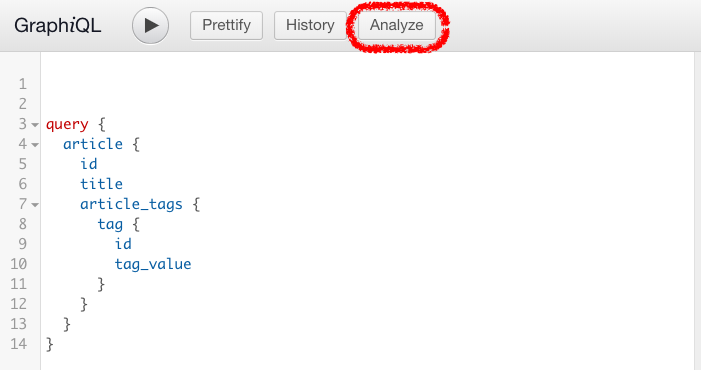
Do take this feature for a spin and let us know what you think. We’d love to hear your thoughts on performance for GraphQL APIs in our very active Discord community channel!



