
Working with schemaless data using GraphQL on Postgres
Exploit Postgres schemaless JSON types in your GraphQL queries using the open-source Hasura GraphQL Engine.
TL;DR
Here is a summary of what is covered in this post
- Schemaless data is data that does not conform to a rigid schema. Usually stored as key-value pairs or as JSON. You can use the
JSONandJSONBcolumn type to store JSON data in your tables. - With Hasura GraphQL Engine, you get instant GraphQL APIs on Postgres which you can use to store and retrieve data from the table.
- We use Postgres views to filter on the JSON data
- Mutation operations on the JSON data using GraphQL is not possible at this point of time and hence, to update you need to replace the whole JSON with the new data.
What is schemaless data?
Schemaless data is data that does not conform to a rigid schema. It is usually stored in the form of key-value pairs or as JSON documents.
In a relational database like Postgres, this would mean working with a JSON data type.
When to use schemaless data?
Relational modeling can be used for most applications. But there are some use-cases where storing data as a JSON document makes sense:
- You can avoid complicated JOINS on tables that hold isolated data by storing them as a JSON document.
- If you are dependent on data coming from an external API as JSON, you can avoid the process of normalizing this data into different tables. Instead, you can store this data in the same format and structure that you received it in.
- It also helps in cases where you are dependent on data whose schema is not fixed.
Working with schemaless data on Postgres
PostgreSQL provides two data types to store JSON elements: JSON and JSONB. The main difference between them is their efficiency. JSON is stored as text and JSONB is first decomposed into binary components and then stored. This makes inserts into JSONB slower but parsing of sub elements faster.
Example use-case
Let’s take an example of a case where we have a third party API which provides us with a user’s name and address. The address field can have multiple fields like apartment number, street name, pincode etc. address in this case does not follow a rigid schema.
Problem Statement:
- Find a way to store the complete information provided by the API into a table in our database.
- Provide an API to filter users based on their address pincode.
Solution Overview:
- Create a
usertable with columnsidprimary key,nameandaddress.addresswill be of typeJSONB. - Use the GraphQL insert mutation to insert data into this table.
- Create a view
user_addresswhich shows theidof the user and theirpincodeby retrieving it from the data in theaddresscolumn of theusertable. - Fetch data from
user_addressusing GraphQL.
Alright, let’s get to implementing our solution.
Getting GraphQL APIs over Postgres
We will use the Hasura GraphQL engine for instantly getting GraphQL APIs over Postgres. Click on the button below to deploy the GraphQL engine to Heroku’s free tier.

This will deploy the graphql-engine to Heroku. You might need to create a Heroku account if you don’t have one. The graphql-engine will be running at https://your-app.herokuapp.com (replace your-app with your heroku app name).
Console
The Graphql engine comes with an admin UI called the Console . You can use the Console to build the backend for your application.
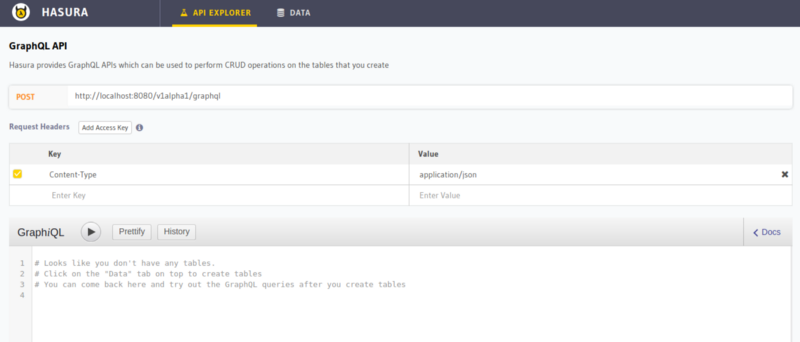
It is running at the /console endpoint of your graphql-engine URL, which is, in this case, https://your-app.herokuapp.com/console. The landing page of the console looks something like this:
Creating a table to store JSON data
On the Console, head to the Data tab and click on Create Table to create a new table.
user table:
idInteger Primary KeynameTextaddressJSONB
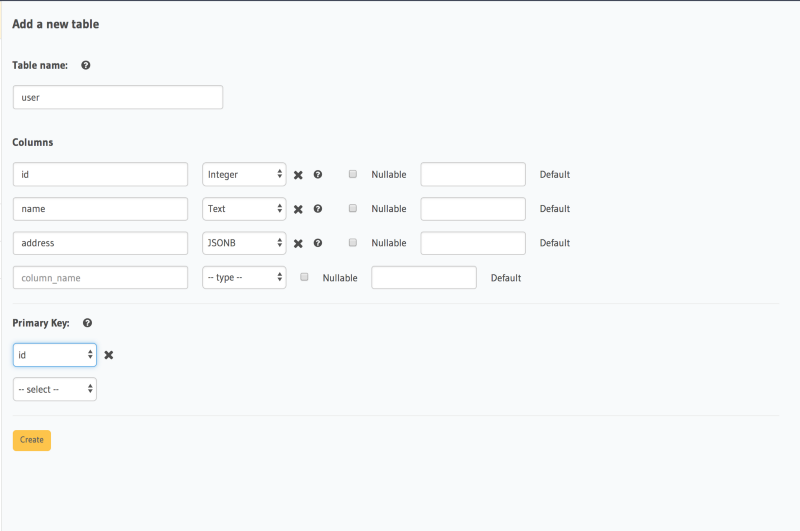
Hit the create button to create the table.
Inserting JSON data into the table
The GraphQL mutation to insert data into the user table will be insert_user(objects: $objects) {
affected_rows
}
}
mutation addUser($objects: [user_input]) {
insert_user(objects: $objects) {
affected_rows
}
}Variable
{
"objects": [
{
"id": 1,
"name": "Jack Smith",
"address": {
"house_number": "112",
"house_name": "XYZ Apartments",
"street_name": "ABC Street",
"city": "Bengaluru",
"pincode": "123456"
}
}
]
}Note: You can try out GraphQL APIs in the API Explorer of the API Console.
Fetching data based on JSON properties using GraphQL
Currently, we cannot directly filter data by the different properties of the stored JSON. We can however, create a view which holds all of this data and then query that view.
Head to the Data tab on the API Console and click on SQL from the left. Run the following SQL command.
CREATE VIEW user_address AS
SELECT id as user_id, address->>'pincode' as pincodeFROM "user";Note: Ensure that you check the Track Table checkbox before running the query so that you can use Data APIs to query the view.
This will create a view called user_address with user_id and pincode as columns.
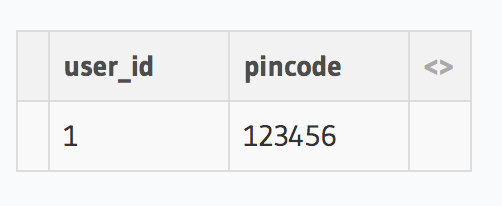
We can now fetch data from this view just like you would from a table.
query user_on_pincode{
user_address(where: {pincode: "123456"}) {
user_id
pincode
}
}Filtering from the user table
You can also directly filter and fetch data from the user table based on the pincode. You need to add the user_address view as an object relationship to the user table.
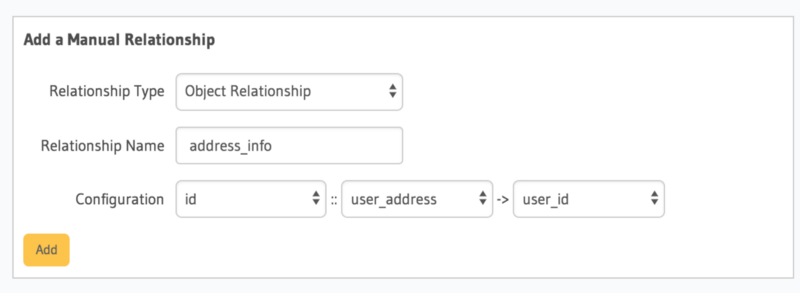
To do this, head to the Data tab in the API Console. Click on user from the panel on the left. Click on the Relationship tab and hit the Add a manual relationship button. In the form that comes up, enter the following information
- Relationship Type will be
Object Relationship - Relationship Name can be “address_info”
- Configuration:
id :: user_address -> user_id
You can now filter the user table by pincode.
query get_user_by_pincode {
user(
where: {
address_info: { pincode: "123456" }
}
) {
id
name
address_info {
pincode
}
}
}Updating JSON data
Currently, there is no direct support to directly manipulate data inside of the JSON. To update, you will have to replace the whole JSON document using the an update mutation.
mutation update_user_address {
update_user(
where: {id: 1}
_set: $new_address
) {
returning {
id
address
}
}
}Variable
{
"new_address": {
"address": {
"house_number": "120",
"house_name": "NEW XYZ Apartments",
"street_name": "NEW ABC Street",
"city": "Bengaluru",
"pincode": "456789"
}
}
}Hopefully, this served as a good introduction to working with schemaless data on Hasura. To learn more about the JSON and JSONB data types, you can check out the Postgres docs here.
If you have any questions or suggestions, do not forget to drop in a comment!



